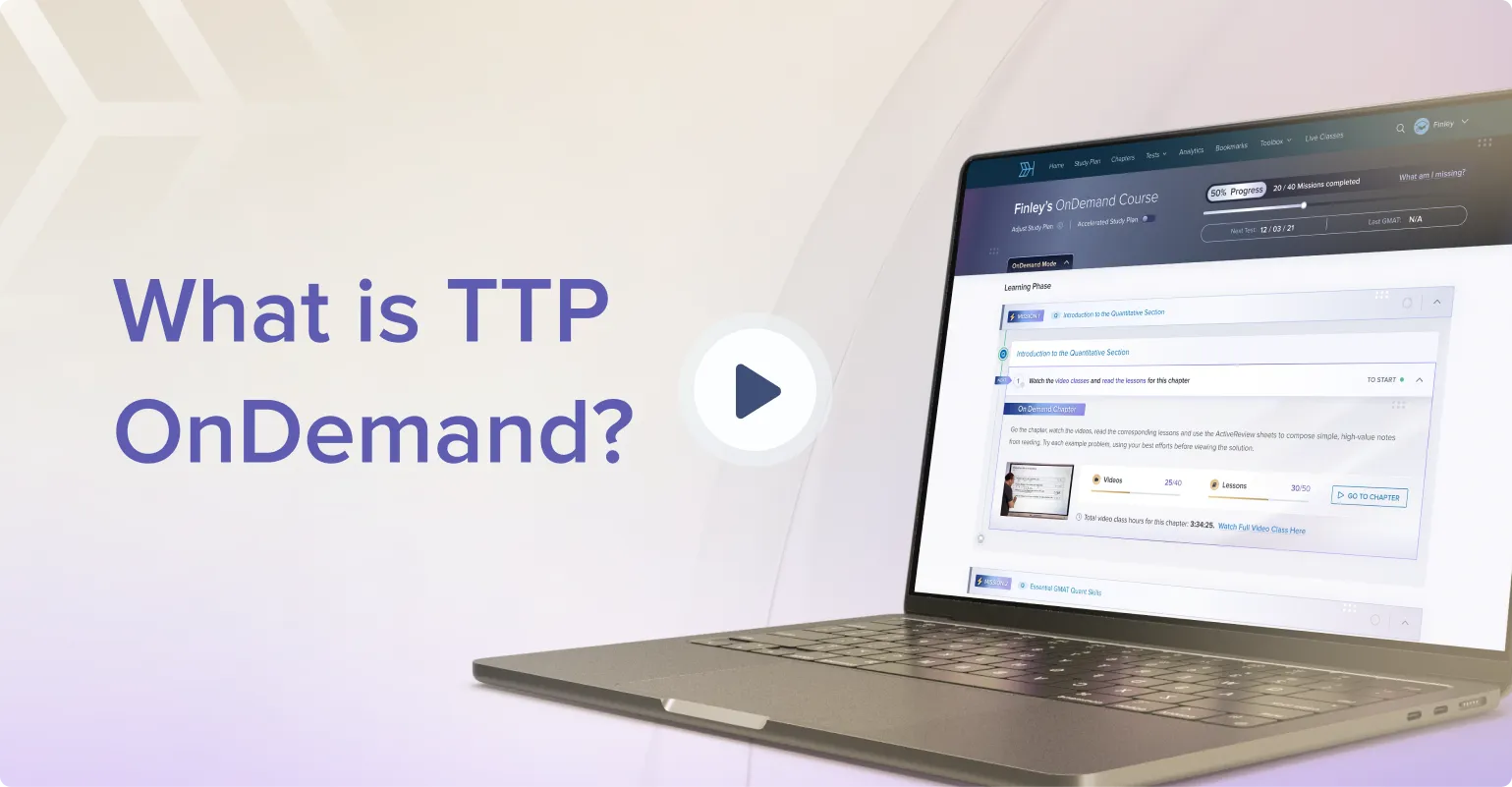
The test does not perform in such a simple manner, but in general getting more questions right results in more difficult questions going forward and getting more questions wrong results in less difficult questions. But it does not work in quite the way you have indicated.
This is from Veritas Vice President of Academic Programs Brian Galvin and I think it exactly answers your question.
"Basics of Adaptive Scoring
If your understanding is "get a question right, the next one is harder; get that one wrong, the next question is easier", you're not "wrong", but you're only partially there. That thinking seems to support a percent-correct calculation in a lot of ways: if you get a "Level 5" question right you'd get a Level 6 question next. Get that right and you'd see Level 7, and then if you get the next two wrong you'd be back at Level 5 again. 2 right, 2 wrong in any order, you'd think, would get you to the same place.
But that's not really how it works. Say you did, in fact, get the first "average" question right. At this point the system already has good evidence (albeit one data point's worth) to suggest that you're above average. So its next question is going to try to determine how far above average, not to confirm whether its earlier data point is correct. So if you answer that next question wrong, you don't go back to "average". At this point the system has two data points to evaluate you: one that says "above average" and another that says "but not way, way above average". So the system will likely see you closer to the 70th percentile, not all the way back to the 50th.
We've always been fans of the "Twenty Questions" analogy. If you were playing the road trip game of Twenty Questions and had narrowed the candidate down to "a US president", you might try to determine which era by asking if he was president after 1900. If the answer comes back "yes", then you'll likely want to figure out just how recent he was president, segmenting the remaining 113 years by asking "was he president after 1960? If the answer comes back "no", you wouldn't start thinking back to presidents in the 1860s because your data points already suggest that it's not one of those, so you'll narrow your search even more between 1900 and 1960.
That's in large part what the GMAT scoring algorithm is doing. If its data suggests that you're above average, it's looking to pin in a score in the same way, with this important caveat - it knows that you'll give it bad information from time to time. Sometimes you'll make a silly mistake on a problem you should get right, and sometimes you'll guess right on a question you should get wrong. So the algorithm has to be more flexible than the game of Twenty Questions. And it does so by using probability and statistics."